
บทความ : รัสรินทร์ เมธาเฉลิมพัฒน์
วิศวกร ทีมระบบไซเบอร์-กายภาพ (CPS)
กลุ่มวิจัยไอโอทีและระบบอัตโนมัติสำหรับงานอุตสาหกรรม (IIARG)
เนคเทค สวทช.
บริษัทยักษ์ใหญ่ทั่วโลกกำลังลงทุนเพื่อนำเทคโนโลยี Machine Learning มาใช้ในกระบวนการผลิตเพื่อให้ได้ผลลัพธ์ที่น่าพอใจ ธุรกิจจำนวนมากกำลังใช้ประโยชน์จากเทคโนโลยีนี้ในหลาย ๆ ด้าน และในอีกไม่กี่ปีต่อจากนี้การประยุกต์ใช้งาน Machine Learning ในภาคอุตสาหกรรมจะแพร่หลายมากขึ้น เพราะสามารถช่วยสร้างผลลัพธ์ที่ดีกว่าและช่วยแก้ไขปัญหาต่างๆได้อย่างเหมาะสม เนื่องจากอุตสาหกรรมการผลิตมีความซับซ้อนมากขึ้นและมีการพัฒนาอย่างต่อเนื่อง ซึ่งการรักษาให้เครื่องจักรและกระบวนการผลิตคงสภาพการผลิตสินค้าที่มีคุณภาพจึงเป็นสิ่งสำคัญที่โรงงานอุตสาหกรรมต้องปรับตัวให้เข้ากับยุคสมัยและนำ Machine Learning เข้ามาใช้ให้เกิดประโยชน์สูงสุด
Machine Learning คืออะไร?
อธิบายง่าย ๆ ได้ว่า Machine Learning คือการใช้ข้อมูลเพื่อทำให้เครื่องคอมพิวเตอร์สามารถเรียนรู้ได้ด้วยตัวเอง โดยแบ่งออกเป็น 3 ประเภท คือ
1. Supervised Learning หรือการเรียนรู้แบบชี้นำด้วยข้อมูล เป็นการฝึกสอนเครื่องคอมพิวเตอร์โดยใช้การใส่ข้อมูล (input) เข้าไปแล้วมีผลลัพธ์ (output) ออกมา ซึ่งแบ่งแยกย่อยได้อีกเป็น 2 ประเภทหลักๆ คือ Classification และ Regression Classification คือการจำแนกประเภทของข้อมูล 2 กลุ่มหรือข้อมูลที่ไม่มีความต่อเนื่องโดยใช้ Confusion Matrix เป็นตัววัดค่าความแม่นยำซึ่งผลลัพธ์ที่ได้จะเป็นการจัดกลุ่มชุดข้อมูล เช่น การคัดแยกคุณภาพของผลิตภัณฑ์การจำแนกการจำแนกประเภทของสัตว์ การคัดแยกลักษณะหน้าตาเป็นต้น
Regression หรือการถดถอยจะใช้กับข้อมูลที่มีความต่อเนื่อง ไม่ได้รวมกันเป็นกลุ่ม โดยใช้ค่า Root Mean Square Error (RMSE) ในการวัดความแม่นยำซึ่งผลลัพธ์ที่ได้จะอยู่ในรูปแบบของตัวเลข เช่น การทำนายยอดขายสินค้าล่วงหน้าเพื่อวางแผนการจัดโปรโมชั่นหรือการพยากรณ์อากาศในอนาคตเป็นต้น
2. Unsupervised Learning หรือการเรียนรู้แบบไม่ชี้นำโดยไม่มีข้อมูล เป็นการฝึกสอนเครื่องคอมพิวเตอร์โดยการป้อนเฉพาะข้อมูล (input) โดยให้เครื่องเรียนรู้และค้นพบรูปแบบด้วยตัวเอง การเรียนรู้แบบนี้มักถูกนำไปใช้เพื่อการแยกกลุ่ม (Clustering) กลุ่มลูกค้าสำหรับ Target Advertisement การลดขนาดมิติข้อมูล (Dimensionality Reduction) สำหรับการทำ Dashboard หรือเตรียมข้อมูลสำหรับทำ Supervised Learning ต่อไป
3. Reinforcement Learning หรือการเรียนรู้ตามการกระทำหรือสภาพแวดล้อมที่พบ โดยให้คอมพิวเตอร์ลองผิดลองถูกและปรับปรุงความสามารถจากผลลัพธ์ในรูปแบบรางวัล-การลงโทษ (Reward-Penalty) วิธีการเรียนรู้แบบนี้ใช้กันแพร่หลายใน Gaming Robot, Autonomous Vehicle, Facebook Chat bot เป็นต้น
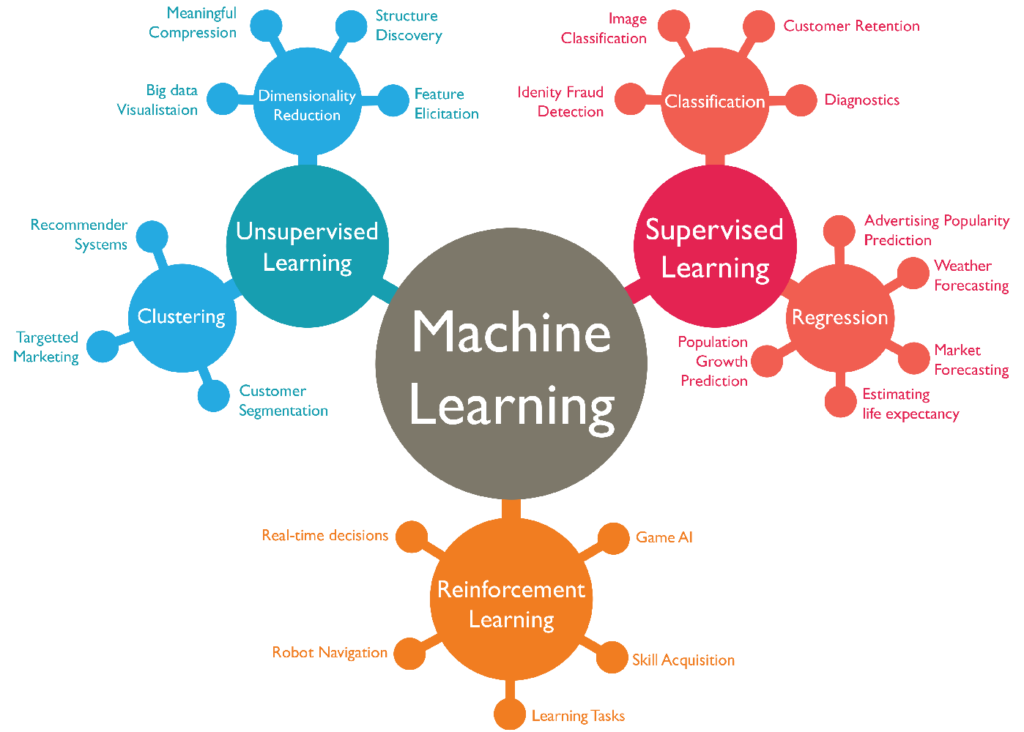
รูปที่ 1 ประเภทของ Machine Learning
ที่มา: https://towardsdatascience.com/machine-learning-types-2-c1291d4f04b1
รูปที่ 1 แสดงการแบ่งย่อยประเภทของ Machine Learning ตามการประยุกต์ใช้งาน ซึ่งล้วนเป็นประโยชน์ต่อภาคอุตสาหกรรมทั้งสิ้น โดยจะขอยกตัวอย่างสองกรณี คือการจำแนกภาพและการจำแนกเสียง ที่สามารถนำไปใช้ได้ในหลายส่วนงานตั้งแต่การตรวจสอบสายการผลิต การควบคุมคุณภาพผลิตภัณฑ์ การบำรุงรักษาเครื่องจักร ไปจนกระทั่งการบริหารทรัพยากรบุคคล
ในกรณีแรก การจำแนกภาพถูกนำไปประยุกต์ในหลายงาน เช่นการตรวจสอบคุณภาพชิ้นงาน การตรวจวัดความเสื่อมสภาพของเครื่องจักร การวัดปริมาณสินค้าหรือวัตถุดิบในคลัง เป็นต้น การจำแนกภาพ (Image Classification) โดยวิธีการ Supervised Learning เป็นการจำแนกข้อมูลประเภทรูปภาพโดยใช้ผลทางสถิติ โดยแบ่งภาพที่ต้องการศึกษาออกเป็นกลุ่มย่อยตามชนิดหรือประเภท (Class) ที่ต้องการจำแนก แล้วนำไปใช้ฝึกสอนด้วยอัลกอริทึม Machine Learning ให้ได้ผลลัพธ์ที่มีประสิทธิภาพ โดยอัลกอริทึมที่นิยมในการใช้ทำ Image Classification มีหลายอัลกอริทึม เช่น CNN , VGG16 , ResNet50 และ MobileNETV2 เป็นต้น
อย่างไรก็ดีอัลกอริทึมที่ถือว่าเป็นพื้นฐานของอัลกอริทึมยอดนิยมอื่นๆ ในการทำ Image Classification ก็คือ CNN หรือ Convolutional Neural Network ซึ่งเป็น Deep Neural Network ที่ออกแบบโดยลอกเลียนจากประสาทการมองเห็นของมนุษย์ มีการใช้ Layer ชนิดพิเศษ ที่เรียกว่า Convolution layer ที่ทำหน้าที่สกัดเอาลักษณะเฉพาะต่างๆ (Features) ของภาพออกมา เช่น เส้นขอบของวัตถุต่างๆ เพื่อให้เครือข่ายสามารถเรียนรู้ลักษณะของภาพได้อย่างมีประสิทธิภาพและแม่นยำ นอกจาก Convolution layer แล้ว CNN ยังประกอบด้วย Layer ชนิดอื่น เช่น Pooling layer, Dropout layer, Fully-connected layer, ReLu Activation layer การนำ Layer ดังกล่าวมาซ้อนต่อๆ กันด้วยจำนวนและลำดับที่ต่างกัน หรือเปลี่ยน Hyperparameter บางอย่าง เช่น ขนาดของ Filter layer (ซึ่งเป็นส่วนหนึ่งของ Convolution layer) และจำนวน Channel ของ layer นำมาซึ่งโครงสร้าง (Architecture) ของ CNN หลากหลายแบบ เช่น LeNet, AlexNet, VGG, ResNet, Inception Network เป็นต้น
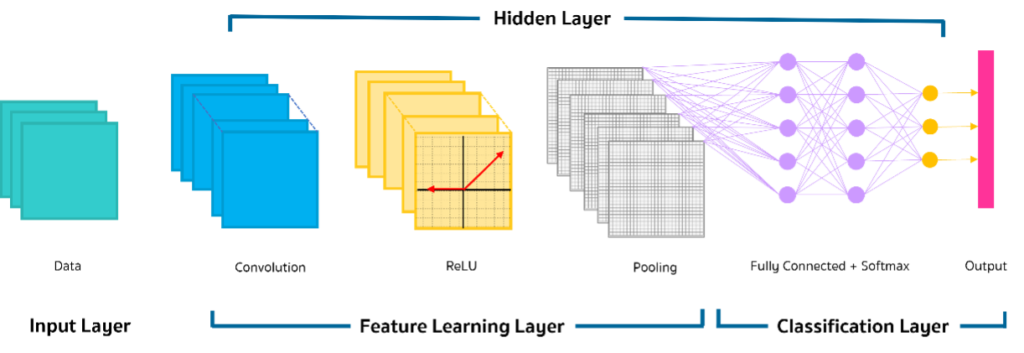
รูปที่ 2 แสดงโครงข่าย CNN. ที่ประกอบด้วย Convolution Layers และ Filters ที่นำไปประมวลผลกับภาพสำหรับเรียนรู้
ชั้นของ CNN มีลักษณะเช่นเดียวกับ Neural Network อื่นๆ ประกอบด้วย Input layer, Output layer, และ Hidden layers จำนวนมากที่แทรกอยู่ระหว่างชั้น จากรูปที่ 2 คือส่วนของ Feature Learning Layers นั่นเอง
หน้าที่ของ Feature Learning Layers
หน้าที่ของ Feature Learning Layers คือทำหน้าที่ในการเปลี่ยนแปลงข้อมูล เพื่อเรียนรู้คุณลักษณะเด่นของข้อมูล โดย 5 Layers ที่พบบ่อยที่สุด คือ Convolution Layer, ReLU Activation Layer, Pooling Layer, Classification (Fully-Connected) Layers และ Batch Normalization Layer โดยแต่ละ Layer มีหน้าที่ดังนี้
1. Convolution Layer
เป็นชั้นที่ดำเนินการกรอง (Filter) เพื่อสกัดลักษณะเฉพาะ (Features) ของข้อมูลภาพออกมา โดยการคำนวณค่า Convolution หรือ Dot Product ระหว่างอินพุตของชั้นกับ Filter หรือ Kernel โดยปกติแล้ว Convolution Layer ของ CNN จะประกอบด้วย Filter มากกว่า 1 ตัวของ Convolutional Filters ซึ่งจะได้ Features บางอย่างออกมาจากชุดข้อมูลภาพ Convolution Layer
2. ReLU: Rectified Linear Unit Activation Layer
หน้าที่ของ Activation Layer คือการเติมความสัมพันธ์ที่ไม่เป็นเชิงเส้น (Nonlinear) ให้กับโมเดลเพื่อให้สามารถเรียนรู้ความสัมพันธ์ที่ซับซ้อนระหว่างข้อมูลอินพุตและผลลัพธ์ได้ ฟังก์ชัน ReLU หรือ Piecewise Linear เป็นฟังก์ชันไม่เชิงเส้นที่นิยมใช้เป็น Activation Function ในปัจจุบันเนื่องจากทำให้การเรียนรู้ง่ายขึ้นโดยหลีกเลี่ยงปัญหา Saturation ใน Activation Function แบบเดิมๆ เช่น Sigmoid หรือ Hyperbolic Tangent โดย สมการของ Activation Function คือ
ReLU(x) = max(0,x)
3. Pooling Layer
เป็นชั้นที่ดำเนินการ ลดขนาดของข้อมูล โดยใช้วิธีการสุ่มตัวอย่างข้อมูล เพื่อป้องกัน Overfitting หรือการที่โมเดลมีความจำเพาะกับข้อมูลที่ใช้ฝึกฝนมากจนเกินไปและไม่สามารถปรับตัวกับข้อมูลที่ไม่เคยเห็นมาก่อนได้ Pooling Layer แบ่งได้เป็น 2 ชนิดคือ Max Pooling และ Average Pooling โดยที่ Max Pooling คือการหาค่าสูงสุดในบริเวณที่ตัวกรองทาบอยู่ซึ่งตัวกรองจะคล้ายกับการทำ Feature Extraction ของ CNN ส่วน Average Pooling คือการหาค่าเฉลี่ยดังนั้นการใช้ค่า Max Pooling จึงได้ค่าที่แม่นยำ และเป็นที่นิยมมากกว่า Average Pooling
4. Classification Layer
Classification Layer หรือ Fully-Connected Layer ชั้นนี้เป็นชั้นสุดท้ายของ CNN ที่มีการเชื่อมต่ออย่างสมบูรณ์ดังแสดงในรูปที่ 2 ดังนั้น ในชั้นสุดท้ายจะมี Output เป็น Vector จำนวน K มิติ, โดยที่ K คือ จำนวนประเภท (Classes) ของภาพที่โครงข่าย CNN จะทำนาย (Prediction) โดยแต่ละค่าภายใน Vector คือความน่าจะเป็นของแต่ละประเภท หรือ กลุ่มที่ต้องการจำแนก ในชั้นสุดท้ายของส่วน Classification Layer จึงมักใช้ฟังก์ชัน “Softmax” เพื่อให้ได้ผลลัพธ์เป็นความน่าจะเป็นที่รวมกันมีค่าเท่ากับ 1
5. Batch Normalization Layer
Batch Normalization คือ เทคนิคที่ใช้เพื่อเร่งความเร็วในการฝึกสอน Deep Neural Network ด้วยการ Normalize แต่ละค่า Input ของ Activation Layer ที่อยู่ภายใน Deep Neural Network ให้มีค่าทางสถิติใกล้เคียงกันในแต่ละ Batch ของข้อมูล วิธีการนี้จะทำให้การปรับน้ำหนักของโมเดลไม่กระโดดไปมาในขณะฝึกสอนด้วยข้อมูลในแต่ละ Batch ช่วยให้โมเดลลู่เข้าสู่จุดที่ทำงานได้เหมาะสมเร็วขึ้น
จะเห็นได้ว่าการทำงานของอัลกอริทึม CNN ในแต่ละ Layer มีโครงสร้างที่เฉพาะตัวซึ่งทำให้มีความสามารถในการสกัด Feature จากข้อมูลได้มากยิ่งขึ้น เหมาะกับการทำ Classification กับชุดข้อมูลที่มีความซับซ้อนมากเป็นพิเศษ แต่ในขณะเดียวกันการเพิ่มจำนวนชั้นของ CNN ให้มีความซับซ้อนก็มีข้อเสียคือทำให้ฝึกสอนโมเดลได้ยากและใช้เวลานานและทรัพยากรมากขึ้น ดังนั้นการจะเลือกใช้อัลกอริทึมนี้เพื่อทำ Machine Learning นอกจากต้องดูความเหมาะสมของชุดข้อมูล แล้วยังต้องคำนึงถึงทรัพยากรสำหรับรองรับการประมวลผลอีกด้วย
ในส่วนของการจำแนกเสียง (Audio Classification) นั้น ไม่ต่างจากการจำแนกภาพมากนักในแง่ของกระบวนการ โดยเริ่มจากแบ่งชุดข้อมูลเป็นกลุ่มย่อยตามลักษณะ หรือประเภทของเสียง (Class) แล้วฝึกสอน อัลกอริทึม Machine Learning ให้ได้ผลลัพธ์ที่มีประสิทธิภาพเช่นกัน สำหรับอัลกอริทึมที่ใช้งานได้ดีกับการจำแนกเสียง ได้แก่ LSTM (Long Short-Term Memory), SVM (Support Vector Machine) หรือแม้แต่ CNN ที่กล่าวถึงไปแล้วในตอนต้น ก็สามารถใช้ได้เช่นกัน ในที่นี้ขอกล่าวถึงอัลกอริทึมที่ใช้งานกันอย่างแพร่หลายเพราะใช้ข้อมูลไม่มาก ฝึกสอนได้รวดเร็ว และได้ผลลัพธ์ที่ดีคืออัลกอริทึม SVM
อัลกอริทึม SVM
SVM (Support Vector Machine) เป็นตัวจำแนกเชิงเส้น (Linear Classifier) แบบไบนารี่ (Binary) (แบ่งแยกข้อมูลได้ 2 ประเภท) ข้อได้เปรียบของ SVM คือมีประสิทธิภาพในการจำแนกข้อมูลที่มีมิติจำนวนมากได้ นอกจากนี้การใช้ฟังก์ชันเคอร์เนล (Kernel Function) ยังช่วยให้สามารถจำแนกข้อมูลที่มีความคลุมเครือได้อย่างมีประสิทธิภาพ หลักการของ SVM คือการหา Hyperplane ทีที่สามารถแบ่งจุดข้อมูลออกเป็น 2 Class ด้วยระยะห่างที่มากที่สุด (Maximum Margin) ในขณะเดียวก็สามารถแบ่งจุดข้อมูลได้อย่างถูกต้องมากที่สุดเท่าที่จะเป็นไปได้ จากหลักการเดียวกันนี้ยังถูกนำไปใช้สำหรับ Regression อีกด้วย เรียกว่า SVR (Support Vector Regression)
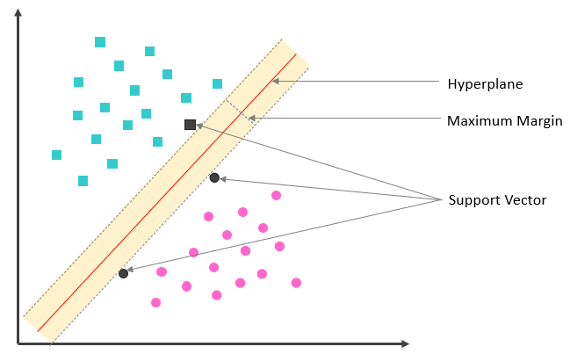
รูปที่ 3 ข้อมูลขนาด 2 มิติซึ่งถูกจำแนกออกเป็น 2 Class ได้แก่ + และClass –
จำนวนมิติของ Hyperplane คือจำนวนมิติของข้อมูล ในกรณีที่ข้อมูลมี 2 มิติ (x,y) ดังรูปที่ 3 Hyperplane คือเส้นที่ ที่มี Margin จากแต่ละ Class มากที่สุด โดยวิธีการที่ใช้ในการหา Hyperplane คือการหาจุดข้อมูลที่อยู่ใกล้กับเส้นแบ่งพรมแดนข้อมูลทั้งสองฝั่งที่จะใช้กำหนดเส้นขอบของแต่ละฝั่ง โดยจุดข้อมูลดังกล่าวจะถูกเรียกว่า Support Vector และการหา Support Vector นี้ขึ้นอยู่กับการกำหนดค่าตัวแปรสำคัญอีกหนึ่งตัวคือพารามิเตอร์ C ที่จะทำให้ Margin จาก Hyperplane ไปยัง Support Vector ที่ยอมรับได้มีขนาดแตกต่างกันดังแสดงในรูปที่ 4 โดยหาก C มีค่ามากจะทำให้ Margin แคบ ทำให้การแบ่งจุดข้อมูลที่ใช้ในการฝึกสอนมีความแม่นยำมากขึ้น แต่อาจทำให้เกิด Overfitting ได้ ในขณะที่หากกำหนด C ให้มีค่าน้อยจะทำให้ Margin กว้างขึ้นทำให้การแบ่งจุดข้อมูลแม่นยำน้อยลง แต่ช่วยกำจัดจุดข้อมูลที่เป็น Outliers หรือ Noise ไปได้ การเลือกค่า C จึงมีความสำคัญโดยต้องพิจารณาให้เหมาะสมกับลักษณะการกระจายตัวของข้อมูล
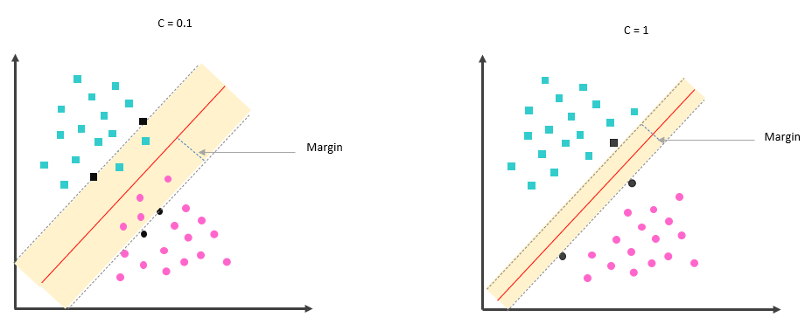
รูปที่ 4 ตัวอย่างการปรับค่า Parameter C ที่มีผลต่อขนาดของเส้นแบ่ง
ในกรณีที่ชุดข้อมูลไม่สามารถถูกแบ่งได้ด้วย Linear Hyperplane ฟังก์ชัน Kernel จะถูกนำมาใช้ในการหา Pattern and Relation ของข้อมูลเพื่อช่วยให้ได้การแบ่งแยกที่เป็น Non Linear ฟังก์ชัน Kernel จึงเป็นฟังก์ชัน Non Linear ที่สร้างจากข้อมูลในมิติที่มีอยู่เดิมแล้วเพิ่มขึ้นมาเป็นมิติใหม่ เช่น z2 = x2+y2 ทำให้ได้ Hyperplane ที่เป็นวงกลม เป็นต้น
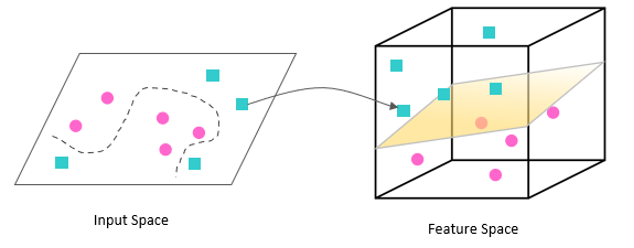
รูปที่ 5 Kernel Function
SVM เหมาะกับ Dataset ที่มี Feature จำนวนมาก แต่มีปริมาณข้อมูลน้อยถึงปานกลาง แต่ในขณะเดียวกัน หากเลือกใช้งานอัลกอริทึม SVM กับชุดข้อมูลที่มีขนาดใหญ่ เวลาที่ใช้ในการฝึก (Training Time) จะเพิ่มขึ้นและอาจส่งผลลบต่อประสิทธิภาพของอัลกอริทึม
การจำแนกเสียงในงานอุตสาหกรรมด้วย Machine Learning สามารถนำไปใช้ได้อย่างดีโดยเฉพาะอย่างยิ่งในการวางแผนซ่อมบำรุงเครื่องจักร ช่วยให้ระบบสามารถทำงานสะดวกมากยิ่งขึ้น เพราะนอกจากจะมีการบันทึกข้อมูลยังมีการคาดการณ์และแจ้งเตือนหากเครื่องจักรขัดข้อง ทำให้สามารถลดค่าใช้จ่ายในการซ่อมบำรุงช่วยเพิ่มประสิทธิภาพของเครื่องจักรและยังช่วยเพิ่มความปลอดภัยให้กับพนักงานที่ต้องควบคุมเครื่องจักรนั้น ๆ อีกด้วย
ดังนั้นเทคโนโลยี Machine Learning สามารถช่วยให้ภาคอุตสาหกรรมผลิตสินค้าที่มีประสิทธิภาพและคุณภาพมากขึ้นและมีการบำรุงรักษาเครื่องจักรที่ดียิ่งขั้น เกิดการคล่องตัวในการผลิตสามารถควบคุมคุณภาพของสินค้า ลดต้นทุน ลดค่าใช้จ่ายในการบำรุงรักษาและยังเพิ่มความน่าเชื่อถือให้กับระบบและกระบวนการ เทคโนโลยีนี้จึงเป็นสิ่งสำคัญที่จะปรับเปลี่ยนอุตสาหกรรมการผลิตตั้งแต่อุตสาหกรรมขนาดเล็กจนถึงขนาดใหญ่ให้มีความทันสมัยและมีประสิทธิภาพที่ดียิ่งขึ้น
ดาวน์โหลดเอกสารเผยแพร่

เอกสารอ้างอิง
[1] Natthawat Phongchit, มาทำความรู้จัก Machine Learning เบื้องต้น,
https://medium.com/@natthawatphongchit/machine-learning-basics-2b38700cb10b
[2] Sumit Saha, A Comprehensive Guide to Convolutional Neural Networks — the ELI5 way,
https://towardsdatascience.com/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way
[3] Natthawat Phongchit, Convolutional Neural Network (CNN) คืออะไร. https://medium.com/@natthawatphongchit
[4] KKLoft, Convolutional Neural Networks (CNN): สร้าง Model เพื่อทำ Image Classification,
https://medium.com/@app.kkloft/convolutional-neural-networks-cnn-สร้าง-model-เพื่อทำ-image-classification-ด้วย-tensorflow-58173661cfeb
[5] PradyaSin, Support Vector Machines (SVM),
https://medium.com/@pradyasin/support-vector-machines-svm-943f9a732a69
[6] scikit-learn developers ,1.4. Support Vector Machines,
https://scikit-learn.org/stable/modules/svm.html
[7] Manu Siddharth Jha, 15 Proven Facts Why Artificial Intelligence Will Create More Jobs in 2021, https://www.mygreatlearning.com/blog/15-reasons-why-ai-will-create-more-jobs-than-it-takes/
[8] James Green, 5 ways you can use Machine Learning in manufacturing,
https://www.ancoris.com/blog/5-ways-machine-learning-manufacturing